Data

In order to support the overall project and the interactive story in particular, Connection Established decided early on to put its ear to the ground and listen to how UVA and Charlottesville communities were reacting to the tumult and confusion that was the year 2020. To that end, the team cast a broad net to gather and, more importantly, record the ways our corner of the world has persisted and resisted through the global COVID-19 pandemic. Two weeks of flattening the curve turned into months and years, and communication via the internet became for many the only sustained communication to be had. Thus we've examined in various ways we connected with each other to talk about literally anything—though the conversation never seemed to stray too far from the viral elephant in the Zoom room—in both unidirectional and bidirectional forms. The importance of local journalism to history and freedom of thought spurred us to include the Charlottesvile Daily Progress and UVA's own Cavalier Daily in the mix, but we knew that could not be the only sources. Social media has, for reasons beyond the scope of this project and site, found a central position in our society and culture today, and, for better or worse, it cannot be ignored. We therefore began collection from the UVA community on Reddit and Twitter, two popular and unique digital forums where Virginians and the world alike shared their opinions. And did they ever.
Data Summary & Motivating Questions
As a general principle we wanted to be as inclusive as possible with our data. Therefore, we searched broadly by keywords like "UVA", "Cville", "mental health", "pandemic", "COVID". In the end we ended up with 730 Cavalier Daily and 884 Daily Progress articles fitting this description dating between March 3, 2020 and May 10, 2021. Social media naturally offered a whole lot more. From February through May 2020 we collected 3232 posts from the /r/UVA subreddit community and 51,998 tweets. In total, the corpus is composed of >3 million tokens (individual words) and >25,000 unique vocabulary from English. The total author count, estimated to the best of our abilities, is no less than 20,000 people.
The sheer enormity of data in Digital Humanities projects can obscure what each and every datum can and does contribute to analysis. At this quantity and working with various genres, we acknowledge that the quality of understanding individual voices in the crowd cannot compare to close reading or textual exegesis. However, we offer an introductory look at what it means to listen to the world all at once—a 21st-century pastime if there is one. So, for a few months we tuned into what our community was discussing, and we asked basic questions, such as "What matters most to people now?", "How they living and describing their lives in these times?", and "What can we learn about our future selves from our current decisions?" Those questions may never be fully answered to our satisfaction, but we hope that the information on this page and this site in general can help everyone come to make sense of our collective experience as well as a bit of our individual experiences alike.
Methods
The overwhelming majority of the data processing was done in the Python programming language. In addition to its straightforward syntax and broad support, Python is well-known for its rich base of tools for Natural Language Processing (NLP), the area of research straddling computer science and linguistics that investigates the usage of natural, i.e. human, languages. In Python, a set of methods (techniques of data manipulation or presentation) is gathered into a what is called a "package" or "library". The most useful libraries used in the data wrangling for Connection Established is featured below.
Toolset
In no particular order of importance, the following packages, tools, and language models were helpful in gathering, processing, and representating the data you see on this page:
- General Data Science
- NLP
- Internet & APIs
- Presentation
Automatated, regular retrieval of data was accomplished by using the Bash scripting language and cron Linux job scheduler on a Raspberry Pi 4 running a headless Ubuntu Server.
Results
The Cavalier Daily
Title Vocabulary
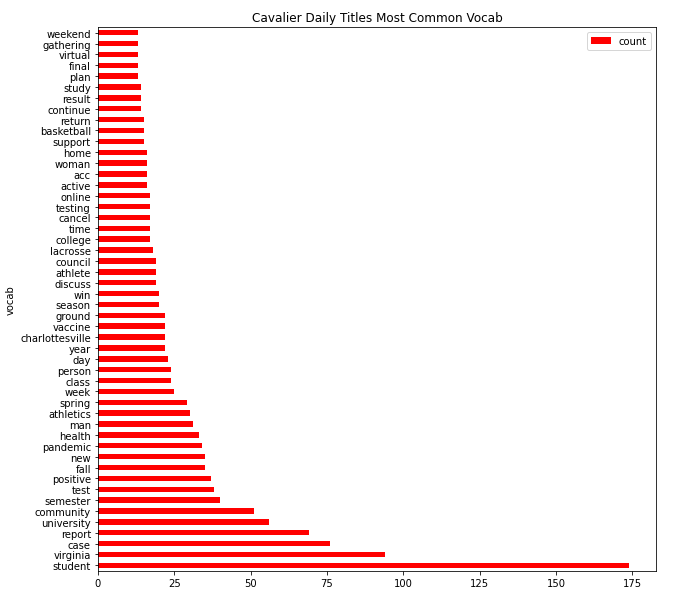
Article Vocabulary
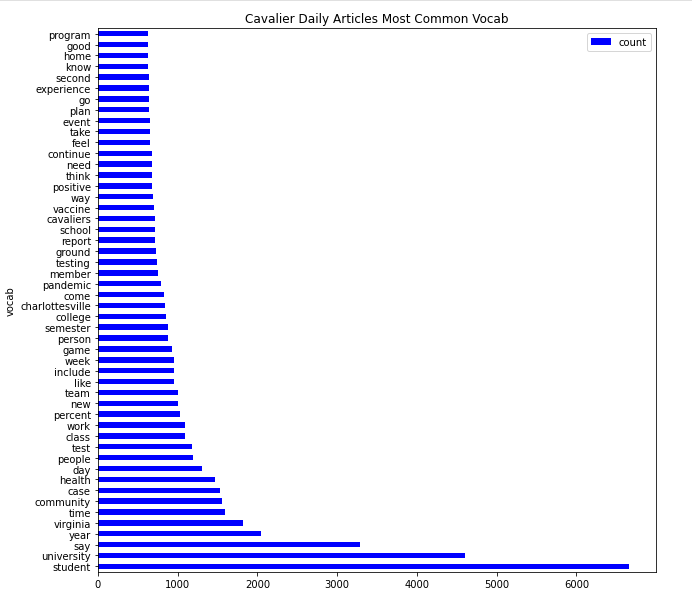
Average Cumulative (Title+Article) Sentiment Analysis
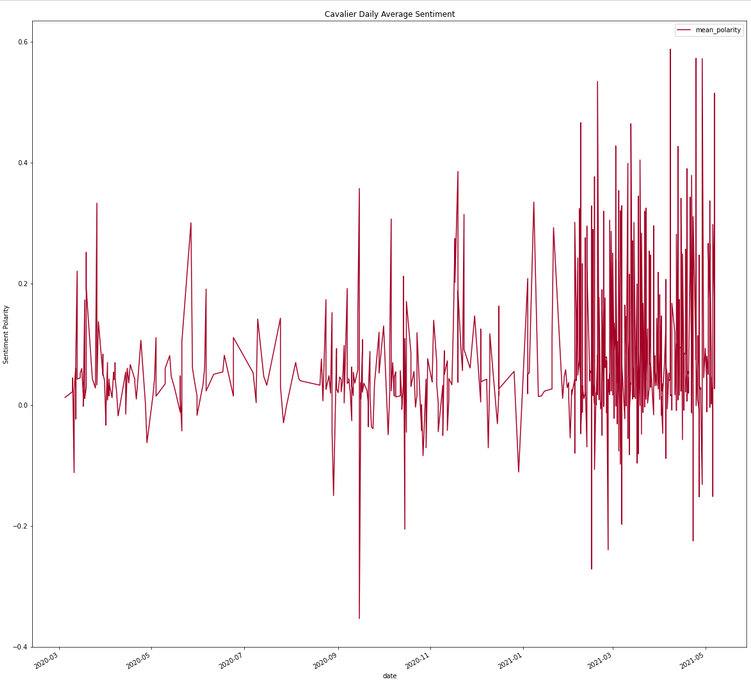
Separate Title and Article Sentiment Analysis
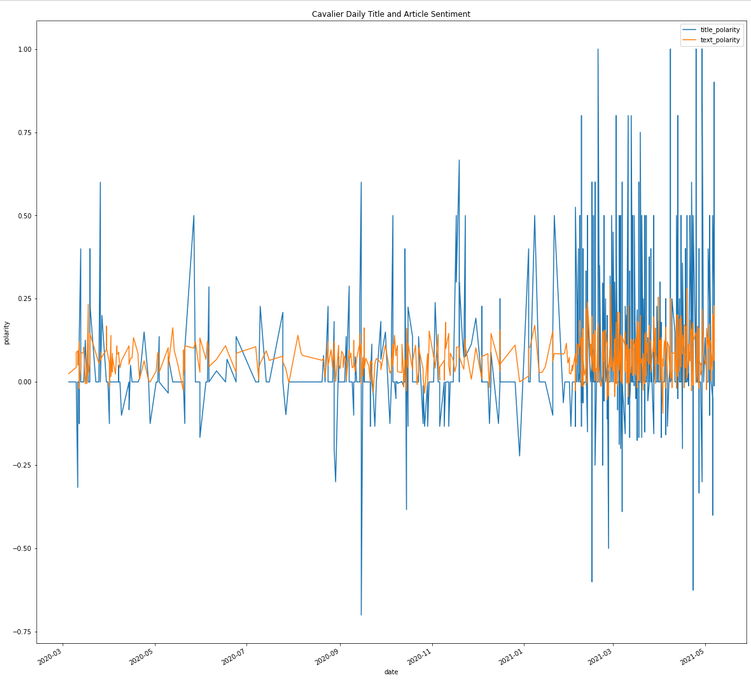
Topic Analysis
CavDaily Title Topics
The Daily Progress
Title Vocabulary
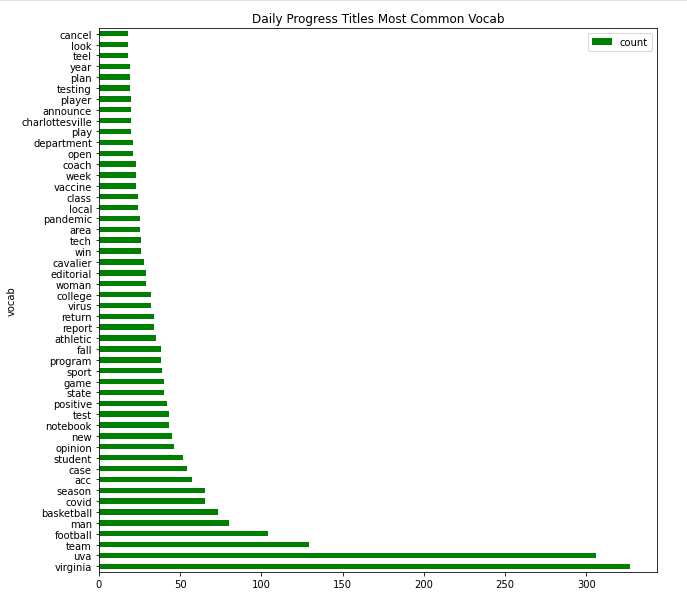
Article Vocabulary
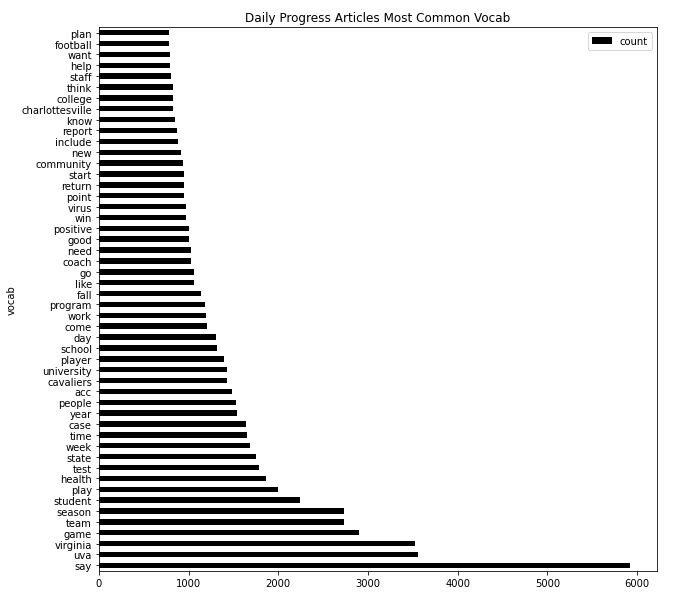
Average Cumulative (Title+Article) Sentiment Analysis
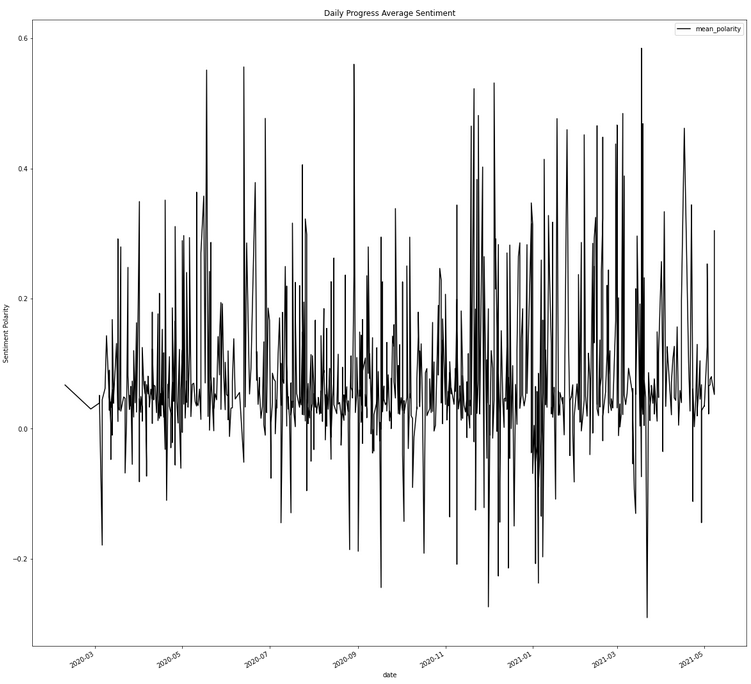
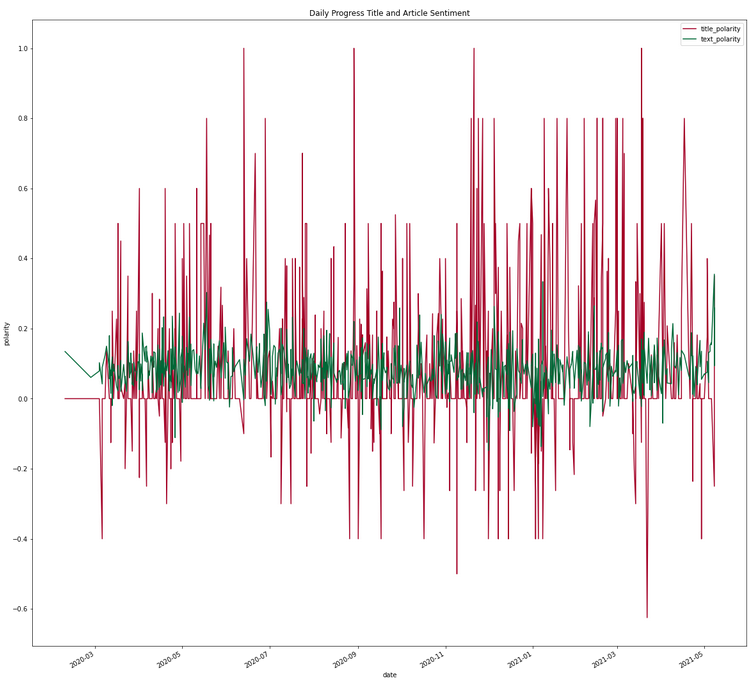
Separate Title and Article Sentiment Analysis